Hullo,
I’d like to truncate a Text, multi-line formatted field, so I can display a snippet of the field in a list of search results.
I started by using the substring function in a composite, but unfortunately it’s not quite cutting the mustard, as the HTML tags from the formatted text (like <br/>) are returned as plaintext in the output.
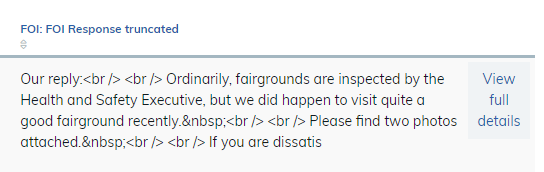
So I’ve set up a rule to copy the value of the Text, multi-line formatted field to a plain Text, multi-line field, using the Strip HTML tags field processor, with the idea of then using this field in the composite.
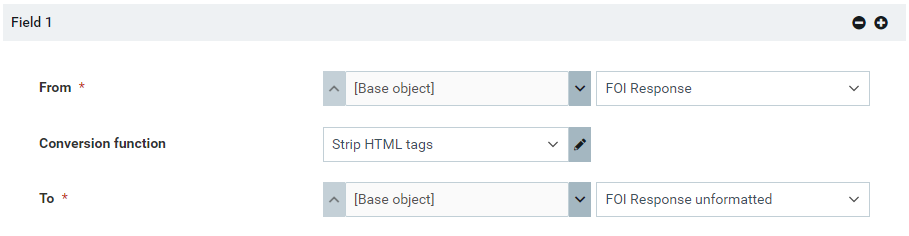
But, although it’s correctly stripping out the HTML tags, it’s not stripping out the HTML character encodings (like for non-breaking spaces and ' for apostrophes)
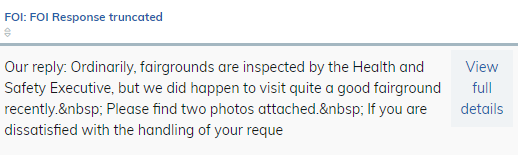
Is there a straightforward way to take multi-line formatted text and the strip out the formatting? I could chain together a sequence of rules and composites to strip out the , and then another to strip out the '… But this way lies madness! Surely there’s a field processor that could take care of the whole thing?